Nous allons continuer aujourd’hui sur ce grand sujet de « DevOps ».
Gestion des déploiements
La gestion de déploiement finalise la chaîne de procédures automatiques en permettant d’intégrer une version sortie de la PIC sur un environnement de production.
De nos jours un simple « copier-coller » des sources sur un serveur FTP n’est plus une option viable de livraison pour différentes raisons :
- la discontinuité de service durant la copie de fichier
- les bugs qui peuvent apparaître durant la phase de dépôt
Notez que deux approches vont apparaître : les services de déploiements centralisé et les services « agentless« . Les deux approches ont leurs avantages et inconvénients. Le premier permet de déporter la charge sur un serveur qui centralise et orchestre de déploiement. Cela peut s’avérer extrêmement utile dès lors que des dizaines de machines sont impactées. Les services « agentless » n’ont pas de serveur d’orchestration de déploiement, ce qui peut donc paraître plus simple à installer, mais il faudra prendre en compte le nombre de machines ciblées par un déploiement.
- Fabric est un outil et librairie Python qui permet le déploiement et la gestion de tâches administratives locales ou via SSH sur différents serveurs. Plus bas niveau que Ansible ou Chef, Fabric trouvé son intérêt dans le fait qu’un fabfile, est codé en Python, un fabfile est un script et non un fichier de configuration. Il est souvent utilisé pour :
- récupérer les paquets et de configurer un environnement.
- des règles pour déployer le projet ou lancer les tests sont aussi une pratique courante.
- Fabric peut aussi être intégré dans un écosystème plus large de déploiement, par exemple en l’utilisant dans des playbook Ansible ou pour initialiser les tests unitaires dans un job Jenkins.
- Ansible est un moteur d’automatisation de déploiement, gestion de configuration, déploiement d’applications, orchestration inter-services, etc. L’un des intérêts majeurs de Ansible est la « non utilisation d’agent », en d’autres termes les machines cibles n’ont pas besoin d’avoir de service spécifique pour être provisionnées par Ansible.
- Il utilise SSH par défaut et se sert de « sudo » pour avoir certains droits si besoin.
- La configuration de tâches est effectuée via des fichiers au format YAML.
- Ansible peut être utilisé via son client en ligne de commande mais aussi en tant qu’outil intégré de déploiement. Par exemple Jenkins.
- Ansible définit une série de concepts identifiés afin de modulariser les déploiements
- Task : tâche à effectuer
- Handler : Idem qu’une tâche mais ne s’exécute qu’à la fin d’une série de tâches et si ces tâches ont effectuer un envoi d’évènement correspondant.
- Variables utilisées par les tâches et handlers définis
- Template permet de créer des fichiers sur les serveurs en utilisant une syntaxe permettant l’utilisation de variables
- Rôle permet de définir les tâches, variables, handlers pour un rôle de machine donné
- GO Continuous Delivery est spécifiquement développé pour configurer et administrer des tâches de déploiement continu. Grâce à ses agents, il peut nativement déployer les tâches sur plusieurs machines
- Server permet contrôler les agents et propose une interface graphique pour paramétrer les Pipelines
- Agents sont contrôlés par le serveur et vont exécuter les Pipelines
- Pipelines sont les étapes de livraison. Déclenchés par des Materials
- Materials sont les environnements extérieurs qui vont déclencher l’exécution d’un Pipline
- Chef et un outil d’automatisation d’infrastructure écrit en Ruby, dont le fonctionnement est analogue à Puppet. Il est multi-plateforme et permet entre autres choses :
- le déploiement de configurations
- l’analyse et les rapports d’états de déploiement
- Chef se découpe en plusieurs parties :
- Chef-Server qui est le serveur central d’approvisionnement
- Chef-Client qui permet d’exécuter des recettes sur les noeuds
- Chef-Automate qui permet l’automatisation de recettes en fonction de workflow ou pipeline
- Puppet est un outil d’automatisation d’infrastructure très largement répandu. Puppet est réalisé en Ruby. Il utilise un langage déclaratif (au lieu de décrire une suite d’actions à réaliser, comme avec les outils d’administration classiques), l’administrateur saisit l’état qu’il souhaite obtenir (permissions souhaitées, fichiers et logiciels à installer, configurations à appliquer), et Puppet se charge automatiquement d’amener le système dans l’état spécifié quel que soit son état de départ.
Gestion des conteneurs et clusters
Le déploiement s’effectue sur des serveurs de production, et bien que ces livraisons puissent s’effectuer sur des serveurs de manière traditionnelle (sans conteneurs), la tendance vise à approvisionner des cluster capables de gérer des conteneurs via Docker, LCX, OpenVZ, etc.)
Tout d’abord parce que les ressources matérielles ne sont plus nécessairement importantes dans le cas d’utilisation de conteneurs applicatifs. Un conteneur ne gérant pas d’émulation matériel ni d’OS à proprement parler, le nombre de micro-services qu’un serveur est capable de gérer est relativement élevé.
Et d’autre part, parce qu’à l’autre bout de la chaîne, du côté développeur, l’utilisation d’un conteneur applicatif est certainement déjà en vigueur. De ce fait, l’image de conteneur utilisée par les développeurs sera la même que celle utilisée sur le serveur.
Aujourd’hui, nombreuses sont les solutions qui vont permettre de s’abstraire du déploiement brut sur un serveur et passer de préférence par une solution d’orchestration de conteneurs. Un simple fichier manifest définit comment démarrer un conteneur.
- Docker, Docker Compose, Docker Swarm
- Docker est une solution de gestion d’images et de conteneurs applicatifs
- L’intérêt majeur de Docker se porte sur sa souplesse et sa communauté qui a rapidement adopté ma solution. Le « Hub », serveur de registre d’images officiel de Docker, propose une série d’images pré-configurées, mais aussi des images spécifiques proposées par la communauté.
- Les images et conteneurs
- Une image propose un service installé dans un environnement spécifique
- Un conteneur crée alors une instance de l’image pour utiliser le service
- Docker-Comopose
- Afin de simplifier la création de conteneur et les liens entre eux, un outil nommé ‘docker-compose », initialement nommé « fig », est aujourd’hui utilisé. Il s’agit de créer un fichier au format « yaml » pour définir quels services lancer, commet les lier, quels ports utilisé, etc
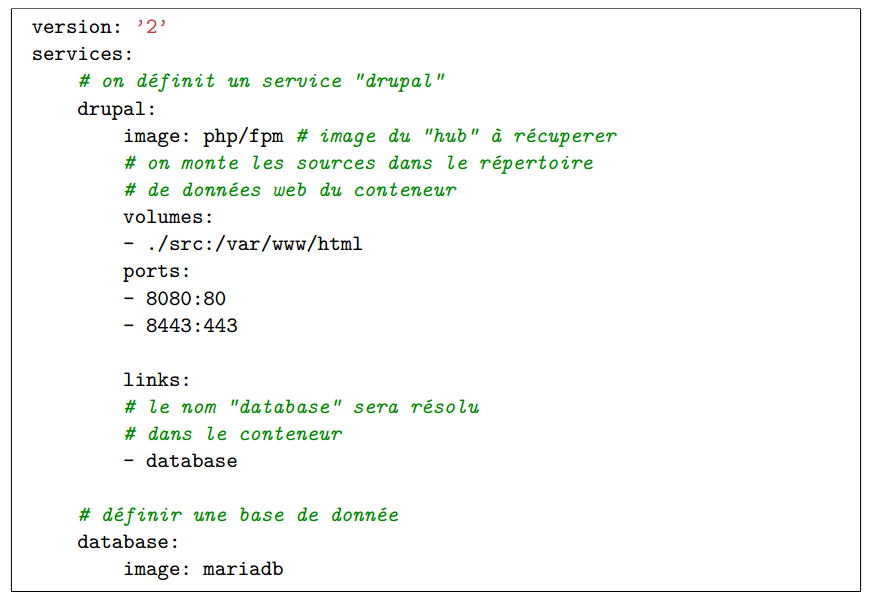
- Ci-dessus sont définis deux services dont les noms sont choisis de manière arbitraire : « drupal » et « database ». Une liaison entre les deux conteneurs est aussi déclarée par la directive « link ». De cette manière, le conteneur « drupal » peut utiliser le nom « database » comme adresse de base de données.
- Les développeurs qui utilisent ce fichier vont alors simplement utiliser la commande « docker-compose up » qui va automatiquement télécharger « pull » les images nécessaires et démarrer les services tels qu’ils sont décrit par les images. Docker repose sur le même principe que « git ». Les images ont des versions (tags) qui permettent de proposer plusieurs alternatives. Par exemple, les images PHP proposent un mode « fpm », un mode « apache », et avec diverses distributions. Mais il propose aussi la possibilité d’adapter les images par le biais d’un fichier nommé « Dockerfile ». Dans ce fichier, il est possible de préparer une configuration spécifique, compiler ou installer d’autres paquets afin de coller au plus prés à la configuration de la production ou pour combler les besoins.
Pour résumer, Docker permet de proposer un environnement de service homogène quelle que soit la distribution utilisée. Les administrateurs systèmes peuvent alors fournir des images ou des fichiers Dockerfile qui se rapprochent au mieux de la configuration de production et assurer alors un déploiement moins risqué.
De plus, les solutions de cluster basées sur Docker tels que CoreOS/Fleet, Kubernetes, Mesos, No-madProject, permettent de mettre en production une réplique exacte de l’environnement utilisé par les développeurs.