Avec les exigences de planning « Time-to-market » et le développement des méthodologies agiles, les besoins d’industrialiser les tests, de fluidifier les déploiements en production et de rapprocher les équipes IT se sont progressivement affirmés.
Si les démarches agiles veulent rapprocher les métiers des équipes de développement, le DevOps a vocation à rapprocher les fonctions de développement (Dev) et d’exploitation (Ops) de L’IT.
Les termes déploiement continu et l’intégration continu sont très présents depuis quelques années. Dans la méthodologie AGILE, ces deux concepts s’intègrent de manière quasi-naturelle et bien souvent les équipes construisent leurs logiciels en suivant ces principes sans en avoir pleinement conscience.
La majeure partie des projets est généralement soumise à la vue de différentes équipes :
- les développeurs de la solution
- les équipes fonctionnelles qui délivrent des spécifications d’intégration et qui, souvent, sont aussi testeurs de nouvelles fonctionnalités
- les opérateurs, administrateurs système, qui vont mettre en production les versions finales
Le DevOps est un mouvement qui est de plus en plus adopté par les équipes techniques dans les entreprises éditrices de logiciels ou les intégrateurs de solutions. Ce principe propose de mettre en place une jonction entre le développeur et l’opérateur ainsi que les intermédiaires pour réaliser efficacement et de manière maîtrisée le produit final.
Pour résumer, nous pouvons définir 3 groupes d’outils qui s’intègrent dans le processus de déploiement continu :
- Le SCM (Source Control Management ) : pour la gestion de contrôle de sources qui permet de rassembler le code source, branches et versions
- La PIC (Plateforme d’intégration continue ) : qui va interfacer le VCS et exécuter une série de tests, bloquer les fusions de branches en cas de problème et forcer la revue de code), vérifier les conventions de code, et générer des rapports.
- La Plate-forme de livraison : qui peut être intégrée à la PIC, elle permet de contrôler une version à livrer et provisionner les cibles de production (déploiement dans un parc informatique, sur un serveur ou sur un cluster)
Tous ces groupes peuvent être un ensemble d’outils, Et c’est sur ce point que peut aussi régner la confusion. Bien que ces trois groupes soient clairement identifiés, les outils qui les portent sont parfois capables de gérer plusieurs couches du processus.
Prenons par exemple Jenkins qui est un outil d’intégration continue, il est aussi très souvent utilisé comme outil de déploiement et peut très bien faire appel à d’autre outil pour provisionner les serveurs de production, après avoir créé l’objet de livraison. Dans ce cas Jenkins va jouer sur plusieurs tableaux et prendre en charge plusieurs aspects du CI/CD.
La PIC va être l’élément central dans un flux de livraison continue puisqu’elle est l’élément qui va déclencher une procédure de déploiement automatisée, un refus de fusion et alerter les équipes.
Intégration Continue
La mise en place d’une plate-forme d’intégration continue (PIC) est indispensable à la mise en oeuvre d’une démarche de « Continuous Delivry », la PIC permettant alors d’assurer la qualité logicielle en continu. En effet, une PIC permet de s’assurer qu’à chaque itération de création de valeur logicielle, un ensemble socle de tests, qui peut être de différentes natures, est effectué.
Les résultats des tests de la PIC pouvant alors déclencher ou non le déploiement sur un environnement de production.
Les sujets de l’intégration continue est très bien couvert par des solutions open source comme Jenkins, avec GIt ou SVN pour la gestion des sources.
Livraison Continue
La démarche DevOps se base sur le fait que le développement logiciel et son aspect production sont fortement imbriqués, et qu’ils doivent par conséquent être gérés ensemble dés le début de projet.
D’une part les besoins actuels de time-to-market imposent un nouveau rythme, bien supérieur, nécessitant industrialisation et automatisation des processus. Aussi Google, Facebook, Amazon, Twitter et autres, mettent en production plusieurs fois par semaine, ou même plusieurs fois par jour.
D’autre part, par rapport à une méthodologie agile classique, il ne s’agit pas uniquement de livraisons pour test, mais bien de livraison en production, données comprises, sans impact, régression ou incident.
Dans ce contexte, on ne peut pas imaginer rester avec des mises en production traditionnelles, nécessitant une intervention manuelle et une supervision humaine dédiée pendant et après la mise en production. Au contraire, avec les outils de Continuous Delivery, chaque livraison en production doit devenir un non-événement, ne nécessitant pas de surveillance particulière.
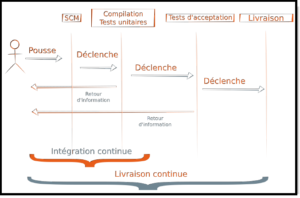
Les gestionnaires de versions
La base d’un flux de livraison continue repose en général sur ce type de service. Le gestionnaire de version connue par « VCS » (Version Control Service) fournit la possibilité à une équipe de développeurs d’injecter du code et de le corriger sans pour autant perdre les corrections des autres développeurs de l’équipe. Il permet aussi l’accès à l’historique, la gestion de conflits, et de créer des branches et des tags permettant d’identifier des livraisons.
Les branches et tags sont essentiels
Lorsqu’il est nécessaire de développer une version qui propose une nouvelle fonctionnalité ou encore pour une version de maintenance / corrective, il faut impérativement être capable de ne pas impacter le « tronc » qui représente le développement de la future version.
Ainsi, il est possible de créer une branche à partir d’une version précise, de développer et créer des tags qui font office de repère de version, et livrer ces derniers sans rapatrier les développements en cours non validés
L’étape qui suivra l’utilisation d’un VCS est la mise en place d’une interface à une plateforme d’intégration continue (PIC).
Les conteneurs et les machines virtuelles
Livrer des applications est un sujet à part entière, mais l’environnement de développement est un thème primordial.
Prenons un projet web développé en PHP. Traditionnellement le déploiement de ce type d’application était réalisé sur des serveurs physiques dédiés sur lesquels tournent un serveur web (Apache ou Nginx), les sources du site étaient déposés sur le serveur. Le moteur de base de données était bien souvent installé sur le même serveur. Le coût d’exploitation et la complexité d’infrastructure était une contrainte pour le développeur qui devait gérer différentes configurations applicatives.
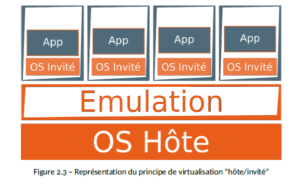
Plutôt que de virtualiser une machine virtuelle complète, il n’est nécessaire que de créer un environnement d’exécution dans lequel un service est démarré pour fournir l’application, il faut rappeler que la technique d’isolation de processus dans un environnement fermé existe depuis des années : le « chroot » permettait déjà de réduire l’impact d’une installation de service dans un répertoire dédié et de plus ou moins l’isoler du reste de l’OS hôte
Le but des conteneurs applicatifs est donc d’isoler un processus dans un système de fichiers à part entière. Seul le strict nécessaire réside dans le conteneur, à savoir l’application cible et quelques dépendances.
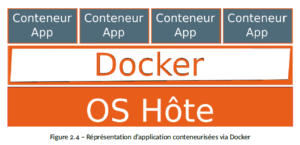
Le revers de la médaille est que la garantie que le développement fonctionne sur l’environnement de production repose sur le fait que les serveurs de production soient en mesure de faire tourner des conteneurs. Si le système n’utilise pas de gestion de conteneurs, l’application sera tout de même capable de tourner et de répondre, mais le paramétrage s’éloigne de celui utilisé par les développeurs.
Certaines solutions de conteneur permettent un démarrage « quasi-complet », par exemple LXC va effectuer une séquence de boot et permet de faire tourner l’ensemble des services nécessaires à une application, mais d’autres comme Docker demandent à ne faire tourner qu’un seul service. Il est fortement recommandé d’utiliser un conteneur par service et de lier les conteneurs entre eux. Cette opération étant simplifiée par Docker-compose
Utiliser des conteneurs impose une réflexion en profondeur de plusieurs aspects tels que la solution de conteneur, la gestion de micro-services sur les postes de développement, la solution utilisée en production et les outils de déploiement
Sur un environnement de production, nous pouvons alors imaginer plusieurs manières d’exploiter une application :
- les applications sont déployées sur une VM proche de celle des développeurs
- les conteneurs sont déployés sur des environnements préparés
- un gestionnaire de conteneur tels que Kubernetes peut aussi être utilisé
Du développement à la production
Le Continuous Delivery suppose la création d’environnements « iso » à partir du développement jusqu’à la production, et aussi au sens inverse, en intégrant les contraintes actualisées de la production jusqu’au développement. Pour cela, les outils open source fleurissent et se complètent : Docker, Jenkins, Ansible, Puppet, Chef,….
Historiquement, ce sont les machines virtuelles qui ont véritablement donné un nouveau souffle aux développeurs. Car ces dernières proposent de faire fonctionner une machine proche, voire identique, à la machine de production.
Puis les conteneurs conquièrent doucement le coeur des administrateurs systèmes et des développeurs pour différentes raisons. Isolation, légèreté, simplicité à intégrer, ….
Docker permet de créer des conteneurs qui peuvent embarquer les logiciels souhaités. Une des révolutions apportées par Docker est qu’il permet de créer très rapidement un micro-service isolé du système hôte sans utiliser de virtualisation à proprement parler.
Mais la virtualisation n’pas disparu, car elle apporte d’autres aspects, notamment en termes de gestion de services ou en terme d’isolation. On citera Vagrant qui permet le démarrage de machines virtuelles (VirtualBox, VMWare,…) en les initialisant selon une configuration voulue.
Les conteneurs et leur légèreté comblent les développeurs qui peuvent démarrer les services, tester différentes versions de framework en quelques secondes
Après le passage en tests, les sources sont donc versionnées et livrées par la PIC. Cette dernière effectue des passes de tests, contrôle la qualité, rapporte et alerte le personnel compétent. Elle va ensuite permettre une livraison automatisée vers un environnement de production.
La production va permettre l’exécution du projet dans les mêmes conditions que celles utilisées par les développeurs de l’application.
On cite quelques outils open source pour la configuration des serveurs et la gestion de déploiement.
- Ansible est un outil de déploiement/configuration à distance
- Puppet lui aussi permet de gérer des configurations et de déployer des solutions sur différents environnements
Un des éléments non adressés par ces solutions porte sur la base de données, sur sa structure et ses données, sa modification dans le temps et sa compatibilité en version avec les différents environnements. Ceci est porté pour le moment par les logiciels applicatifs et pas par les outils DevOps
Avantages de l’Open Source
Toutes ces solutions sont distribuées sous licence open source. Certains ont des fonctionnalités complémentaires en version entreprise. Vraiement l’open source est l’écosystème qui porte l’innovation.
Gestion des sources- SVN
- GIT
- Mercurial
- PIC
- Jenkins
- Gitlab est l’interface de gestion des projets GIT(utilisateurs, projets, pull-requests, forks,…), propose aussi une gestion de rapport d’anomalie
- GitLab CE : Community Edition
- GitLab CE : Entreprise Edition
- GitLab propose désormais la gestion de constructions et/ou de tests via Gitlab-CI, ce dernier propose un mode ‘server-worker’ qui permet de lancer des tests et d’effectuer des actions en fonction es résultats obtenus. Les workers sont capables d’exécuter des tests locaus, sur des conteneurs ou sur des machines distantes (tout comme jenkins).
- Strider a pour particularité d’être développée en NodeJs et utilise MongoDB pour la persistence
Nous allons continuer dans un prochain article sur la partie de gestion des déploiements et les différentes outils liés.